Game to Video: Using Generative AI to Uprender Gameplay
11 Jun 2023Using gameplay footage to control Stable Diffusion’s output
Generative AI is all the rage right now. One area I’m fascinated by is ControlNet’s ability to control the output of Stable Diffusion, an image generation model, using depth maps and segmentation maps. Examples from ControlNet’s github:
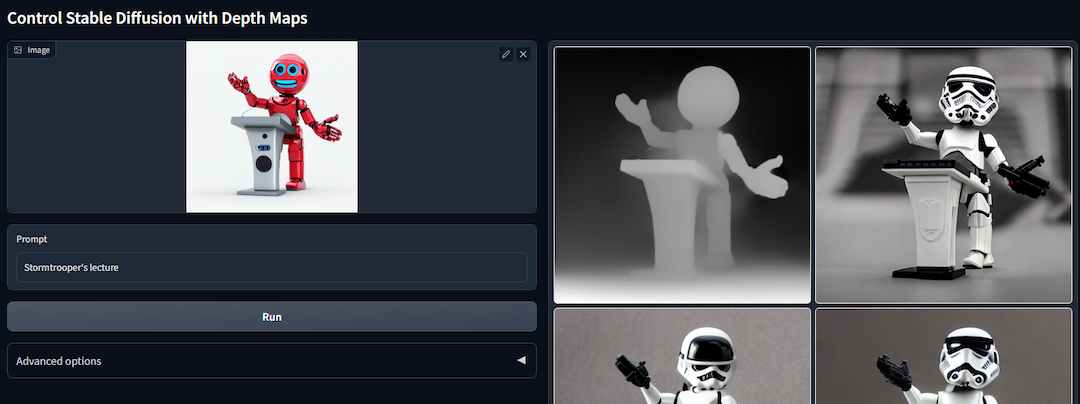
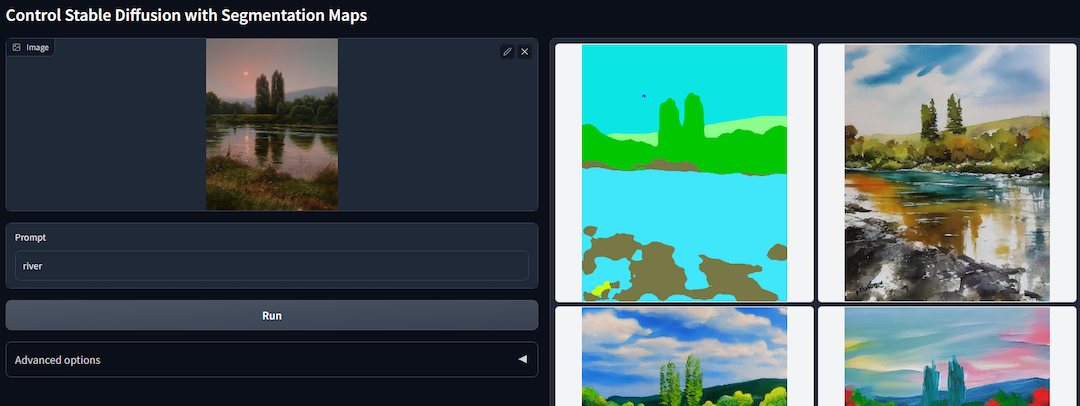
Depth Maps and Segmentation Maps can be generated by game engines, in real-time. I decided to whip up a mini game in Godot, render some frames and movies, and see what uprendering gameplay could look like.
Starting with Image Frames
Below, you’ll see simple first person images of a game with untextured models, rerendered as depth maps and segmentation maps. Scroll to the bottom for higher resolution videos.
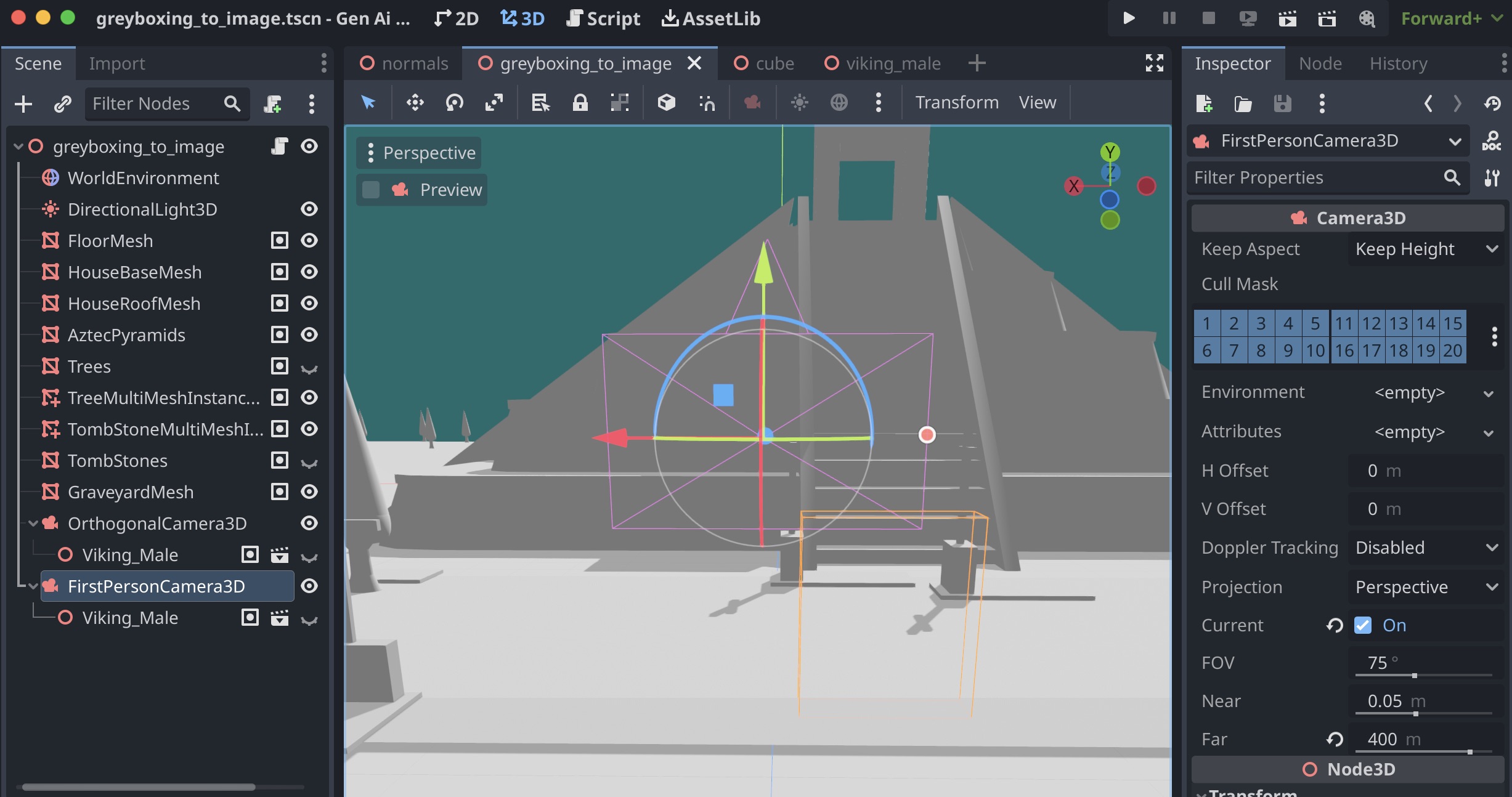


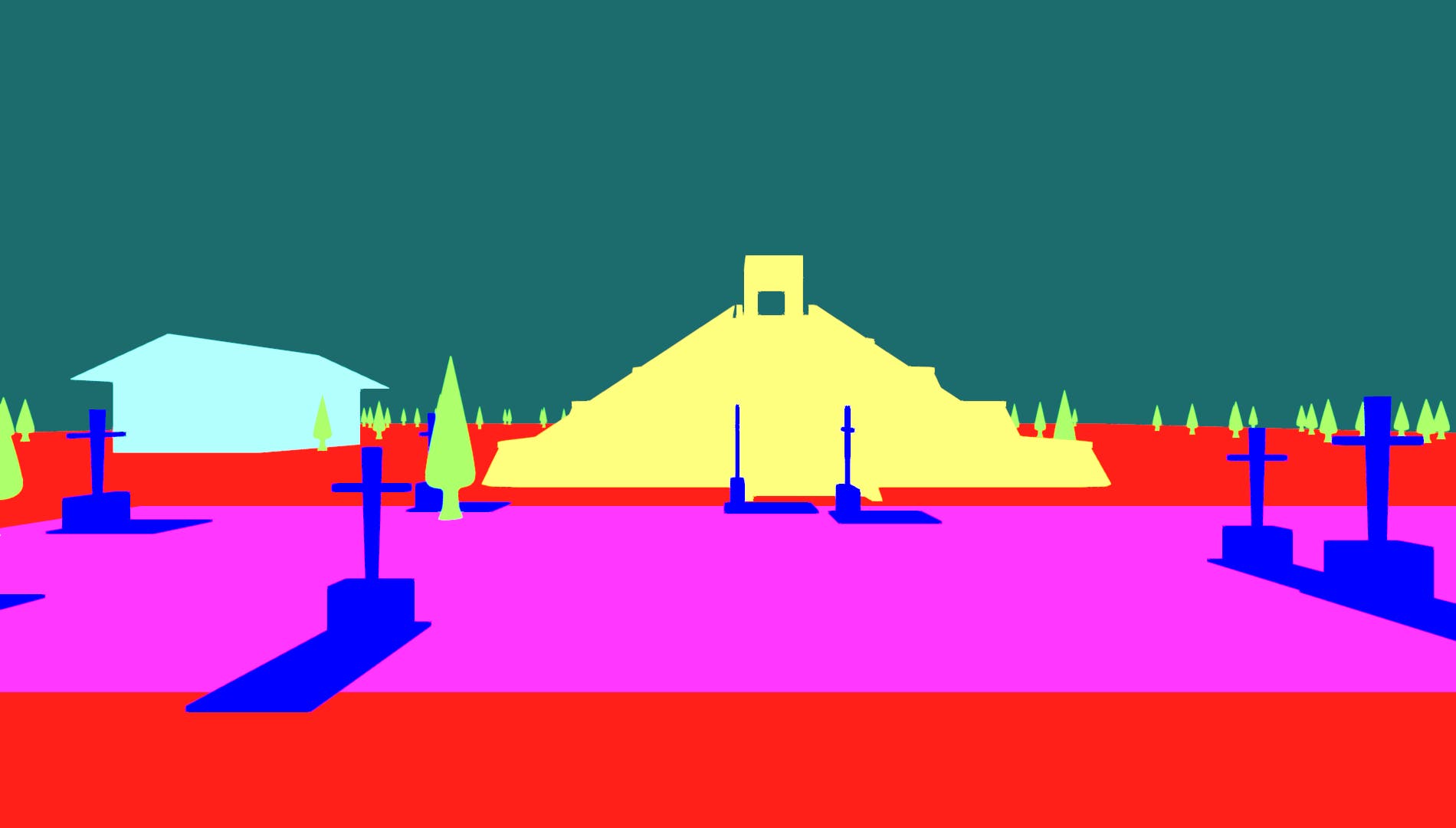
Multi-ControlNet
ControlNet takes in guiding input, like edges, depth maps, and segmentation maps to guide the generated media. One can even use multiple controls to give better direction, like a depth map and a segmentation map. Focusing on single frames for Multi-ControlNet as a starter, the following images were generated:




Flickering videos when sequencing images
Taking the most promising one and creating a sequence of images for a movie had a lot of flickering:
Incorporating TemporalKit would be the next step. But we’re pressed for time over here. Instead, we turned to Runway ML’s video to video.
Upgrading to Videos with Runway ML Video to Video
Below you’ll see the same first person video rendered in three different modes: untextured, depth, and segmentation.
Taking this input, we explored a few different themes and prompts:
Orthogonal Camera of isometric not so successful in video
It seems many image generation models assume a sky backdrop. After searching for a bit, I found a few promising isometric models to generate the following output. Lackluster compared to first person in my opinion.


Thanks for reading this far!
Stay tuned for part 2, and drop a comment below!