Counting Crowds and Lines with AI
19 Nov 2017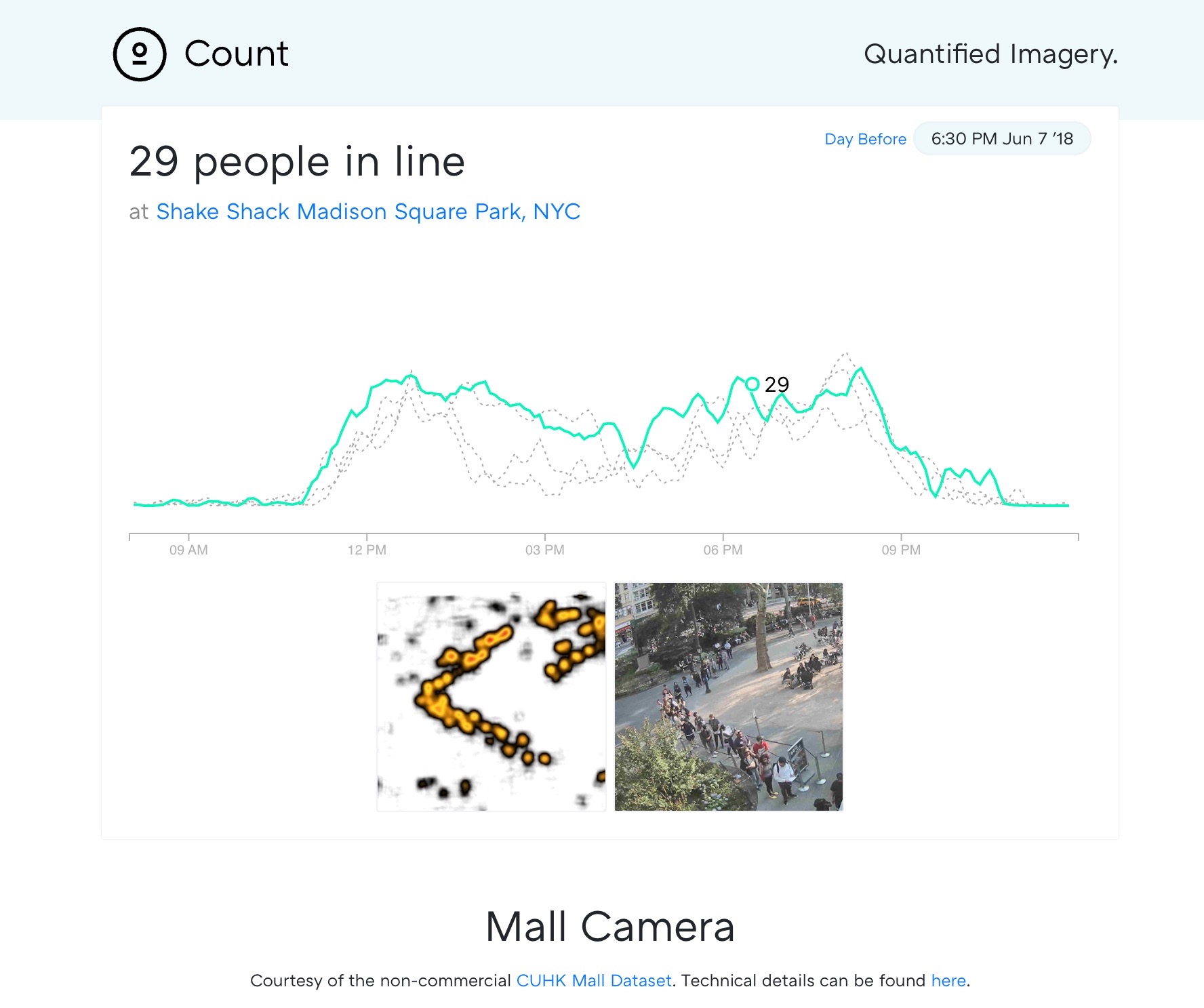
* Data courtesy of the CUHK Mall Dataset
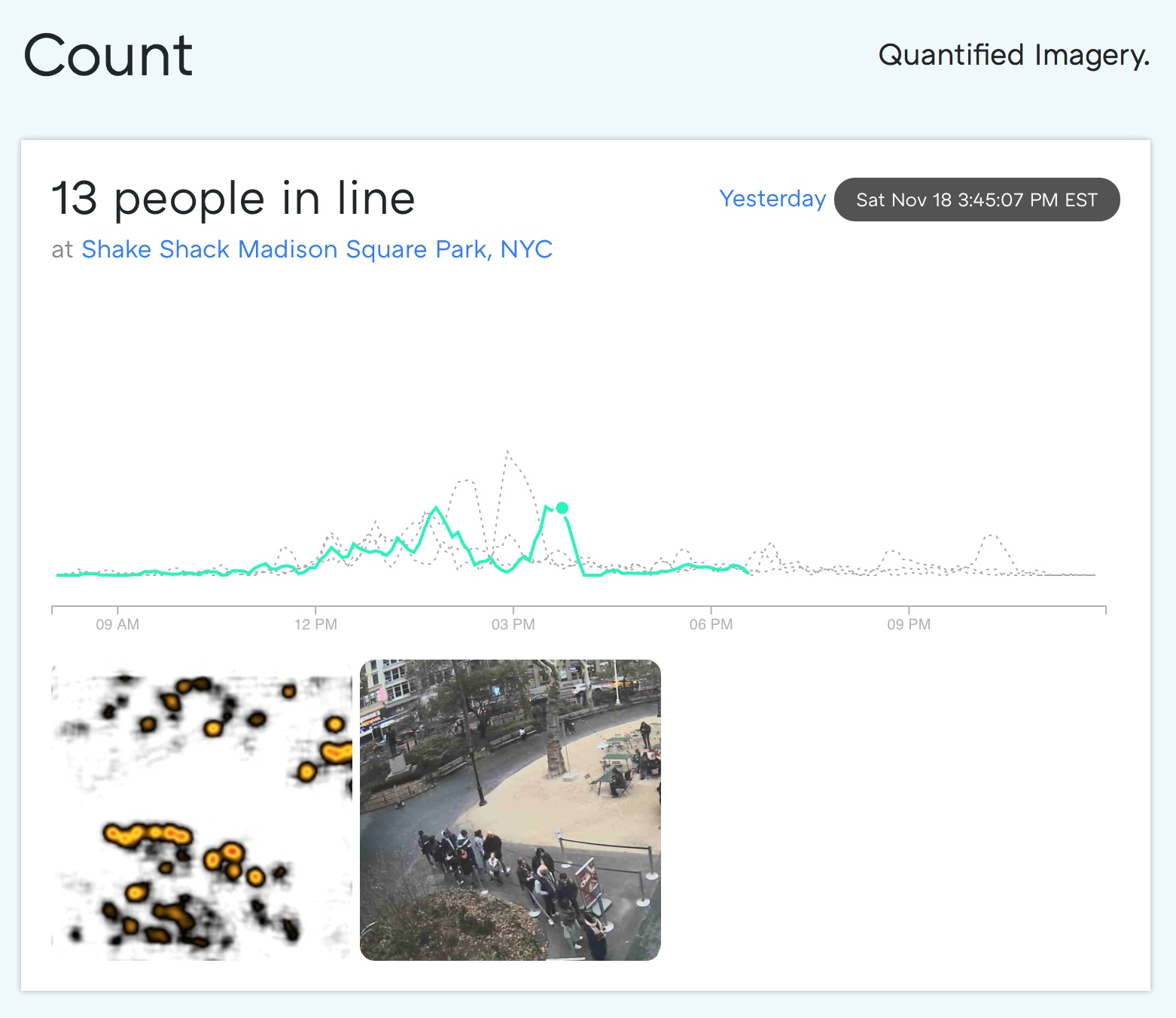
* Screenshot of decommissioned website Count: Quantified imagery SaaS
* Feel free to check out the source code.
* Check out part 2: counting people on your iPhone with CoreML.
In Union Square, NYC, there’s the always crowded burger spot Shake Shack. A group of us would obsessively check the Shake Cam around lunch to figure out if a bite was worth the wait.

Rather than do this manually (come on, it’s nearly 2018), it would be great if this could be done for us. Then, to take that idea further, imagine being able to measure foot traffic on a month to month basis or to measure the impact of a new promotional campaign.
Object detection has received a lot of attention in the deep learning space, but it’s ill-suited for highly congested scenes like crowds. In this post, I’ll talk about how I implemented multi-scale convolutional neural network (CNN) for crowd and line counting.
Why not object detection
Regional-CNN’s (R-CNN) use a sliding window to find an object. High density crowds are ill-suited for sliding windows due to high occlusion:

Further exploration in this approach led me to TensorBox, but it too had issues with high congestion and large crowd counts.
Density Maps to the rescue
Rather than a sliding window, density maps (aka heat maps) estimate the likelihood of a head
being at a location:
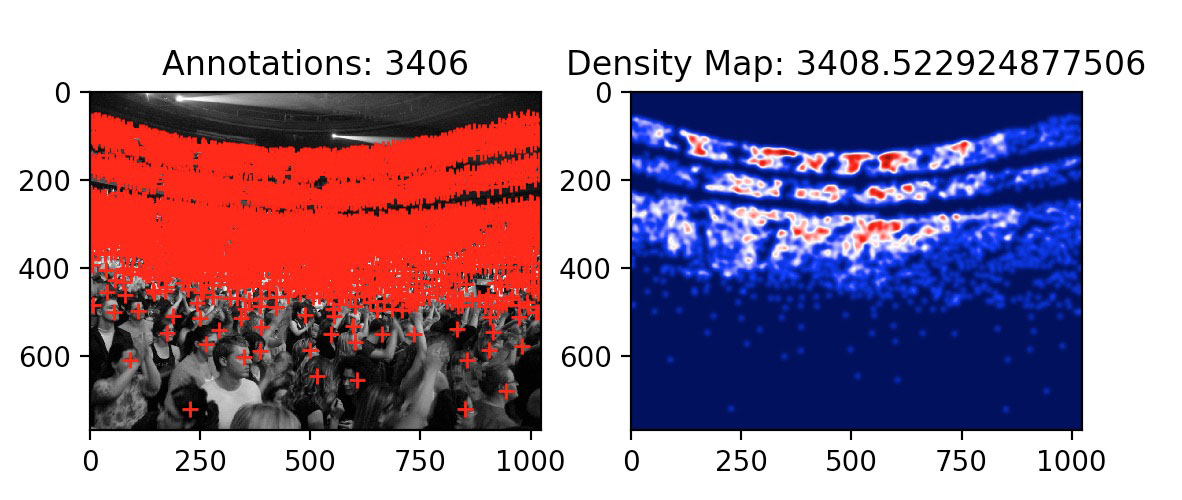
3406 vs 3408? Pretty close!
What’s happening here?
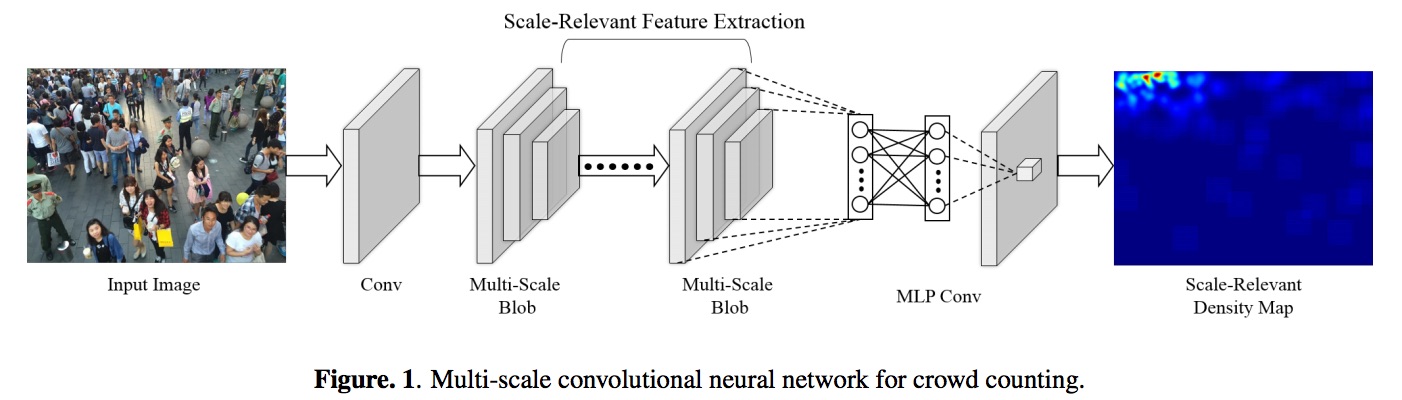
Based on multi-scale convolutional neural network (CNN) for crowd counting, the ground truth is generated by taking the head annotations and setting that pixel value to one, and then gaussian blurring the image. The model is then trained to output these blurred images, or density maps. The sum of all the image pixels then results in the crowd count prediction. Read the paper for more insight.
Let’s look at density maps applied to the shake cam. Don’t worry about the color switch from blue to white for the density maps.
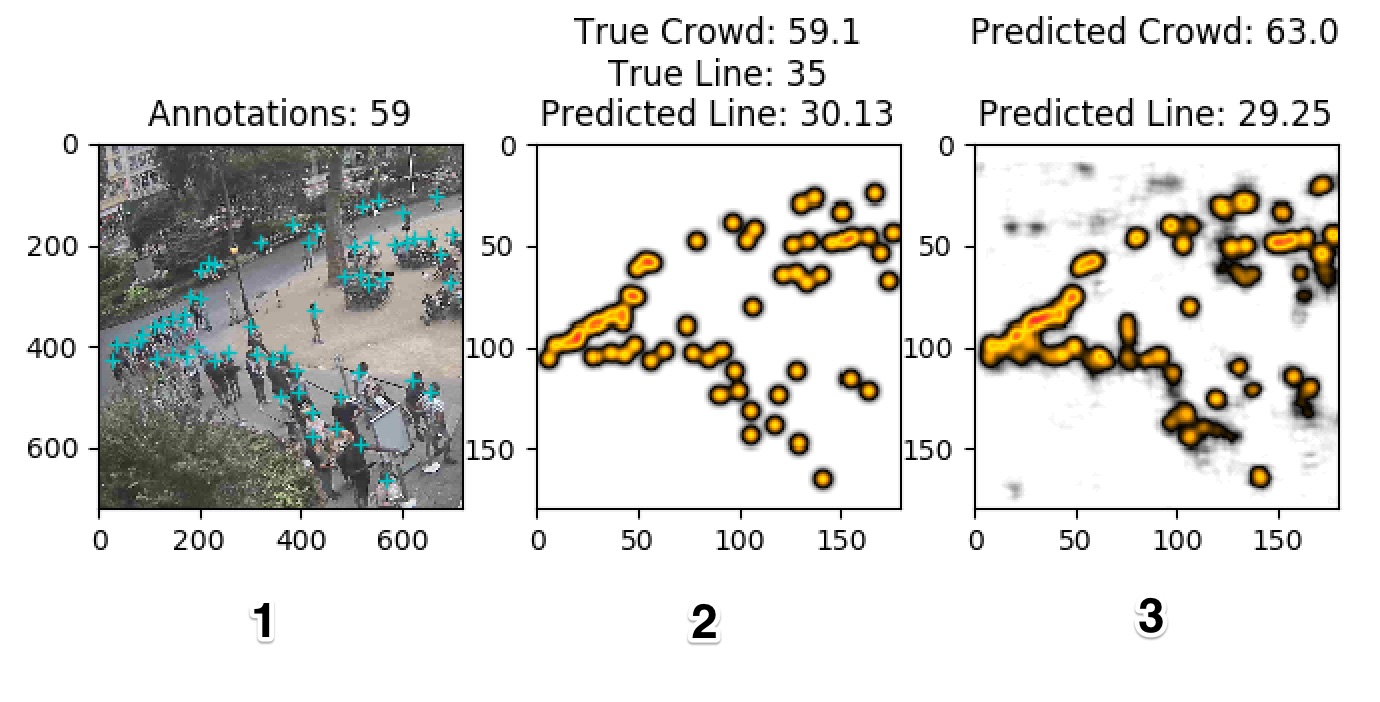
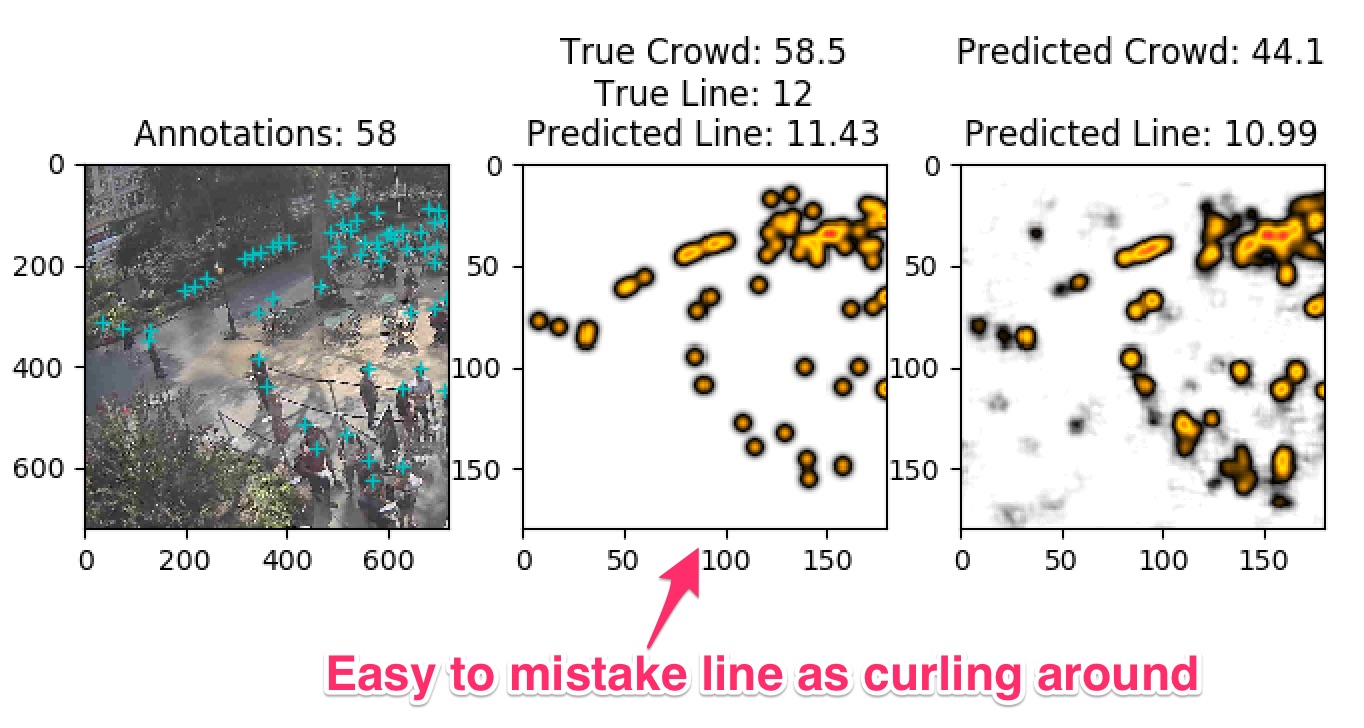
As you can see above, we have:
- The annotated image courtesy of AWS Mechanical Turk.
- The calculated ground truth by setting head locations to one and then gaussian blurring.
- The model’s prediction after being trained with ground truths.
How to get the images?
From your neighborhood Shake Shack Cam of course.
How to annotate the data?
The tried and true AWS Mechanical Turk, with a twist: a mouse click annotates a head as shown below:
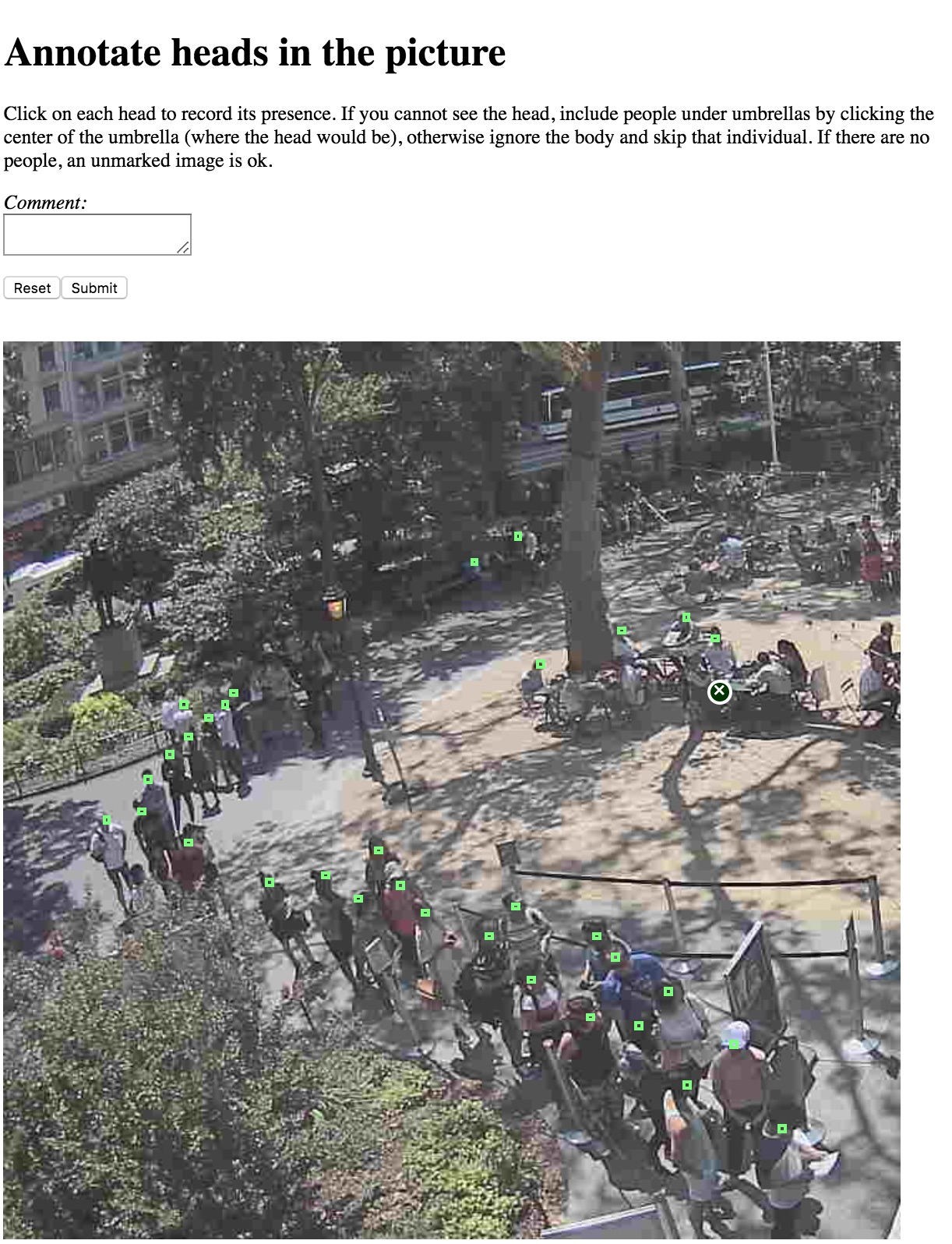
I went ahead and modified the bbox-annotator to be a single click head annotator.
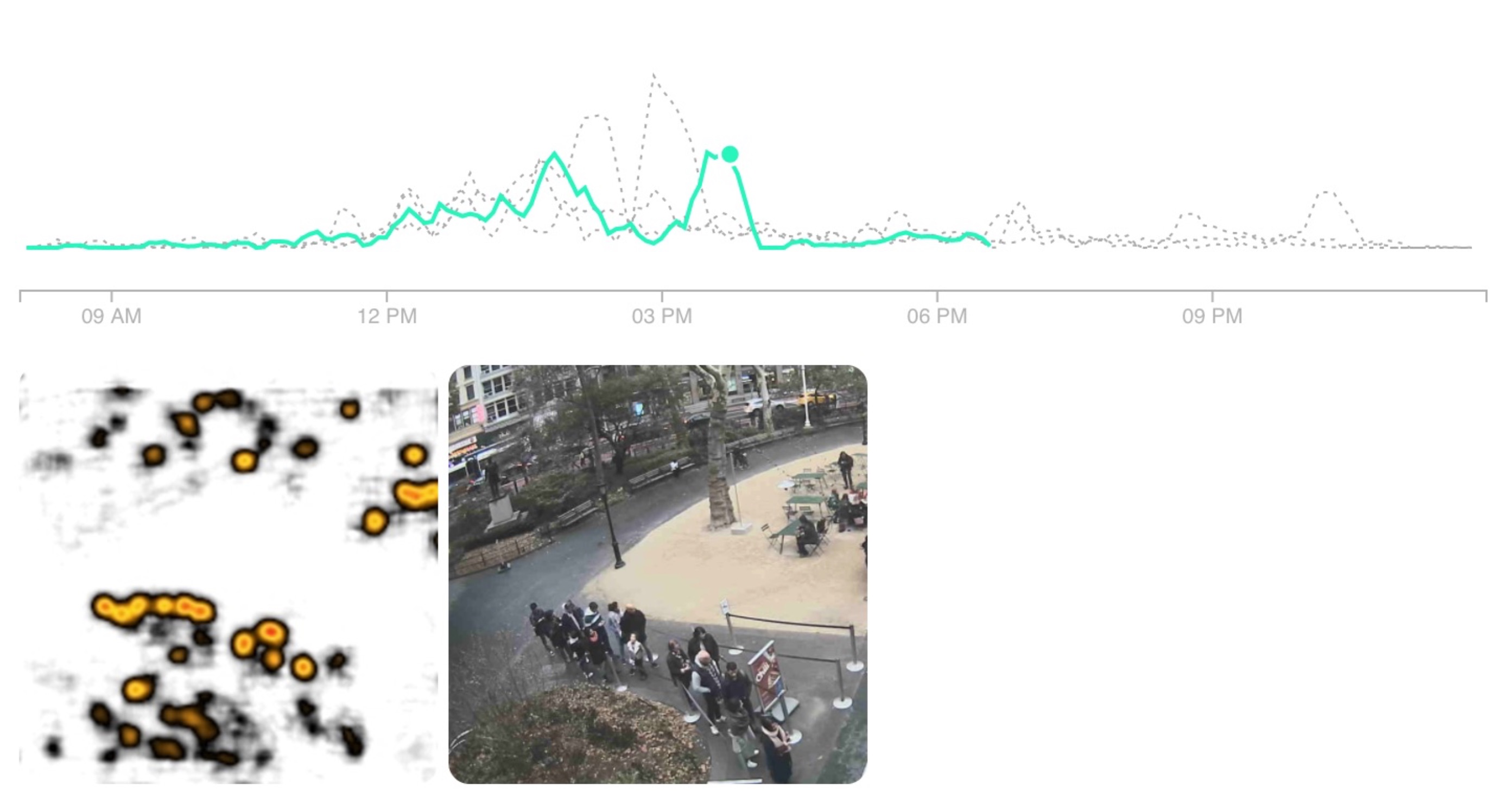
How to count the line?
Lines aren’t merely people in a certain space, they are people standing next to each other to form a contiguous collection of people. As of now, I simply feed the density map into a three layer fully connected (FC) network to output a single number, the line count.
Gathering data for that also ended up being a task in AWS Mechanical Turk.
Here are some examples of where lines aren’t immediately obvious:
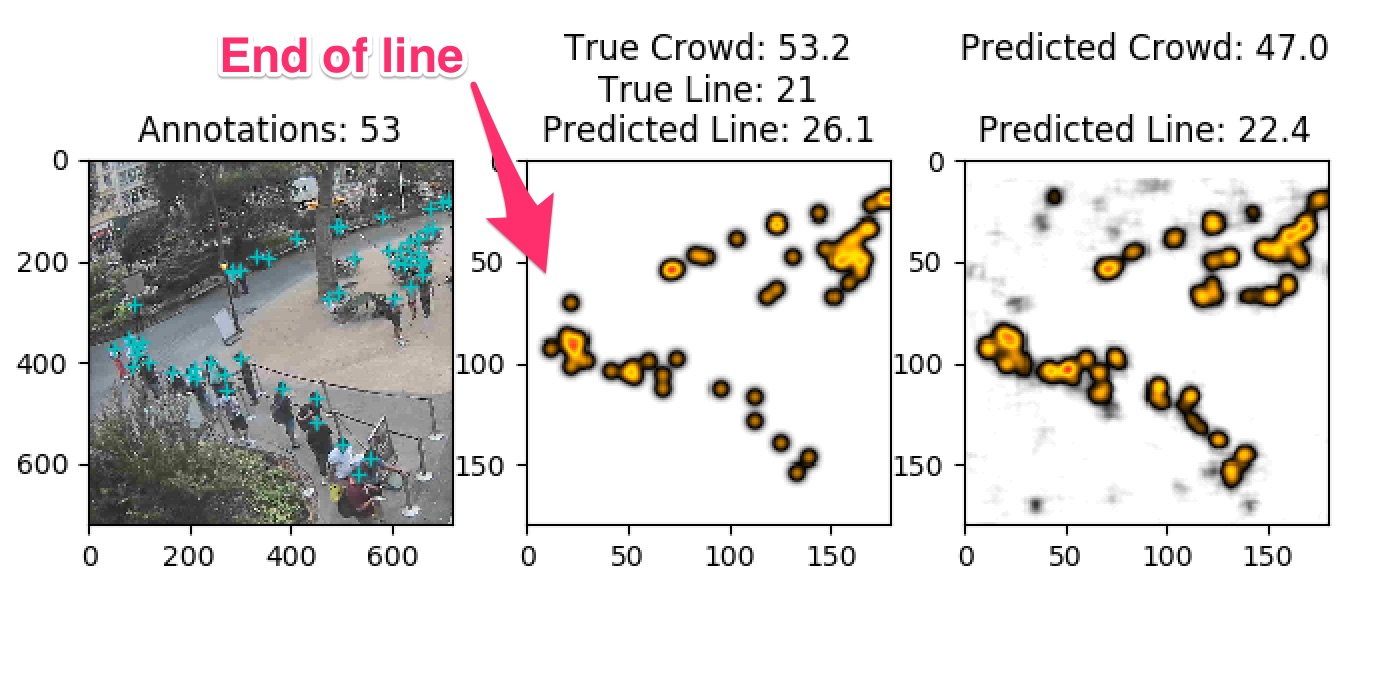
Making a product out of data science
This is all good fun working on your development box, but how do you host it? This will be a topic for another blog post, but the short story is:
- Make sure it doesn’t look bad! Thanks to the design work done by Steve @ thoughtmerchants.com
- Use Vue JS and d3 to visualize the line count.
- Create a docker image with your static assets and Conda dependencies.
- Deploy to GCP with kubernetes on Google Container Engine.
- Periodically run a background job to scrape the shake cam image and run a prediction.
I did the extra credit step of having a Rails application interact with the ML service via gRPC, while integration testing with PyCall. Not necessary, but I’m very happy with the setup.
Unexpected Challenges
These following challenges have contributed to erroneous line predictions:
- Umbrellas. Not a head but still a person.
- Shadows. Around noon there can be some strong shadows resembling people.
- Winter Darkness. It gets much darker much sooner in November and December. Yet the model was trained predominantly with images of people in daylight.
- Winter Snow. Training data never had snow, and now we have mistakes like this:

As I discover more of these scenarios, I’ll know what data to gather for a model retraining.
Check out the site and the source.
Feel free to drop a line below if you have any questions.
References
- Multi-scale Convolutional Neural Networks for Crowd Counting Lingke Zeng, Xiangmin Xu, Bolun Cai, Suo Qiu, Tong Zhang Page PDF
- Fully Convolutional Crowd Counting On Highly Congested Scenes Mark Marsden, Kevin McGuinness, Suzanne Little and Noel E. O’Connor PDF
- Multi-Source Multi-Scale Counting in Extremely Dense Crowd Images Haroon Idrees, Imran Saleemi, Cody Seibert, Mubarak Shah IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), 2013 PDF
- From Semi-Supervised to Transfer Counting of Crowds C. C. Loy, S. Gong, and T. Xiang in Proceedings of IEEE International Conference on Computer Vision, pp. 2256-2263, 2013 (ICCV) PDF Project Page