Moving AI from the Cloud to the Edge with Crowd Count and Apple's Core ML
12 Aug 2018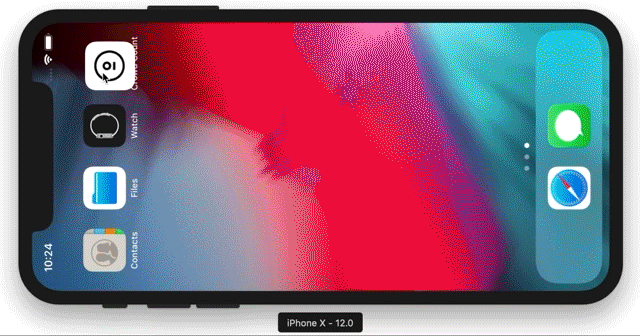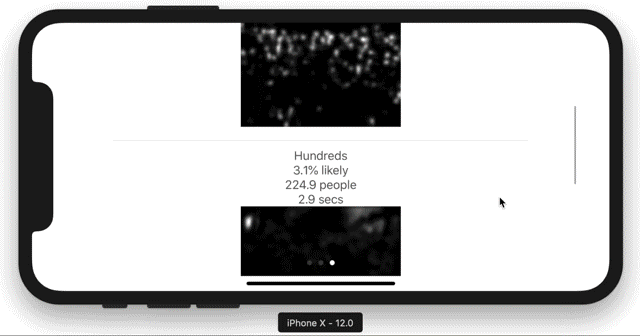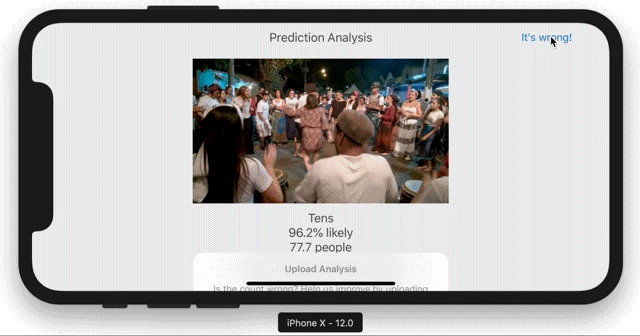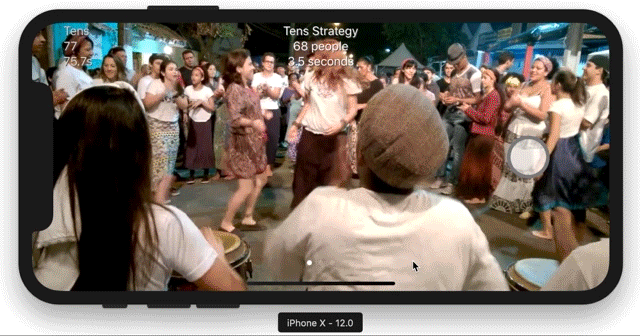
After successfully counting crowds in python, which you can read about here, I took it upon myself to run the very same models on the iPhone with Core ML (ML: Machine Learning). Core ML and MLKit open up a new domain for computing that’s being branded as Edge AI, where neural networks run on a local device (edge) as opposed to the cloud. The source code for this experiment is available here.
Transitioning from a fixed camera (ShakeCam Madison Square Park) to a general purpose iPhone app meant handling a wider variety of input. Are we counting three people or three thousand people? In this article, we’ll go over eight facets of the port, from migrating Cloud AI to Edge AI to handling wildly different inputs:
- Using a two stage ML pipeline to handle different inputs
- First stage: Building the Crowd Classifier with Create ML
- Second stage: Different densities, different prediction models: singles, tens, hundreds+
- Python coremltools to convert Keras to Core ML
- Why an Xcode Playground for Core ML became a macOS App (Playgrounds are too brittle)
- Swift Architecture: RxSwift and MVVM
- Performance: Better than expected
- Promising Future for Edge AI
1. Using a two stage ML pipeline to handle different inputs
iPhone camera input can vary wildly. Are we counting a selfie or a football stadium? Our counting model doesn’t handle that type of variety well. To mitigate this, we tailor make prediction models to accommodate a particular density, and then use image classification to pick the best strategy.
Crowd Classification -> either singles, tens or hundreds crowd prediction -> count of people
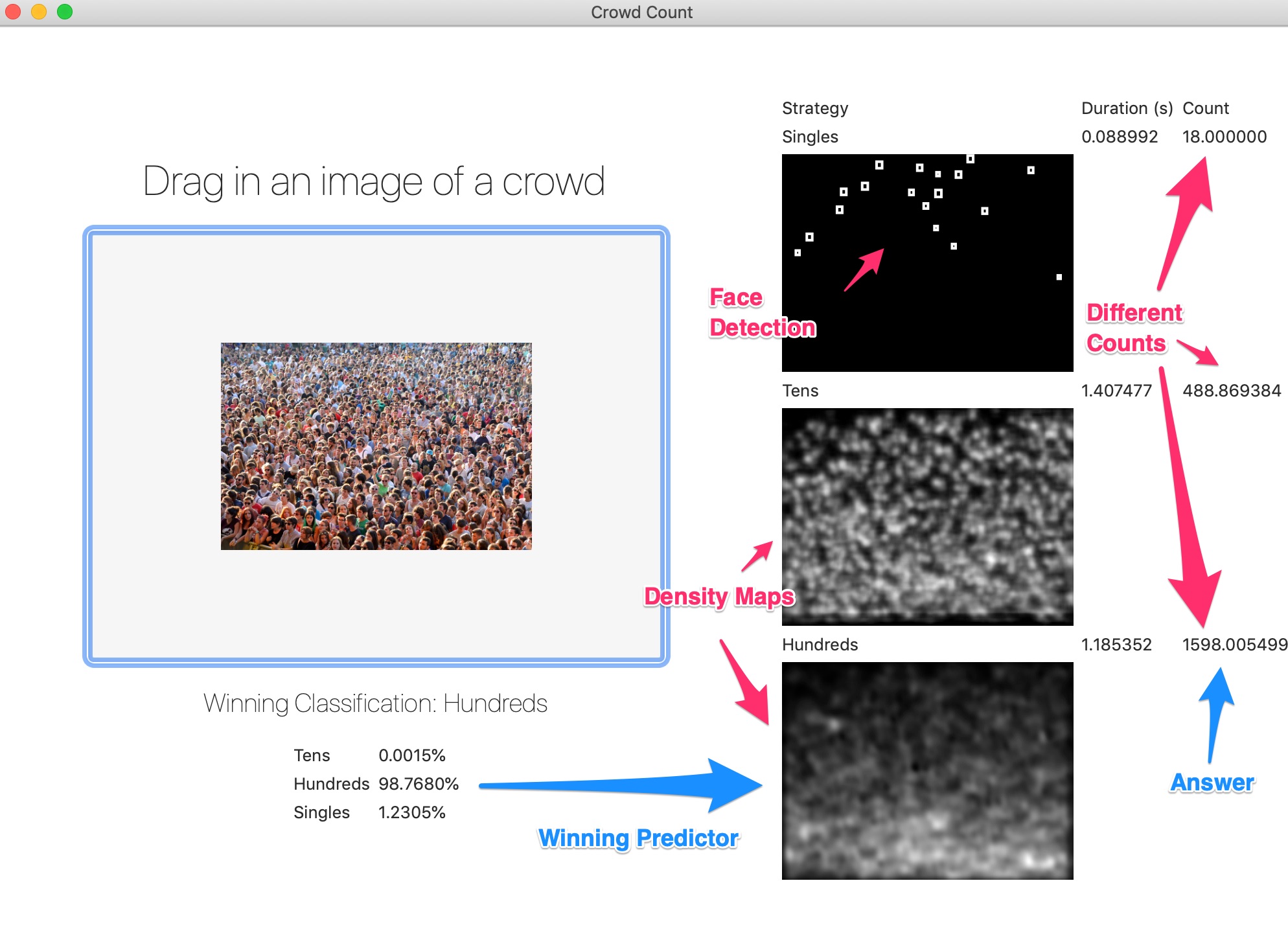
2. Building the Crowd Classifier with Create ML
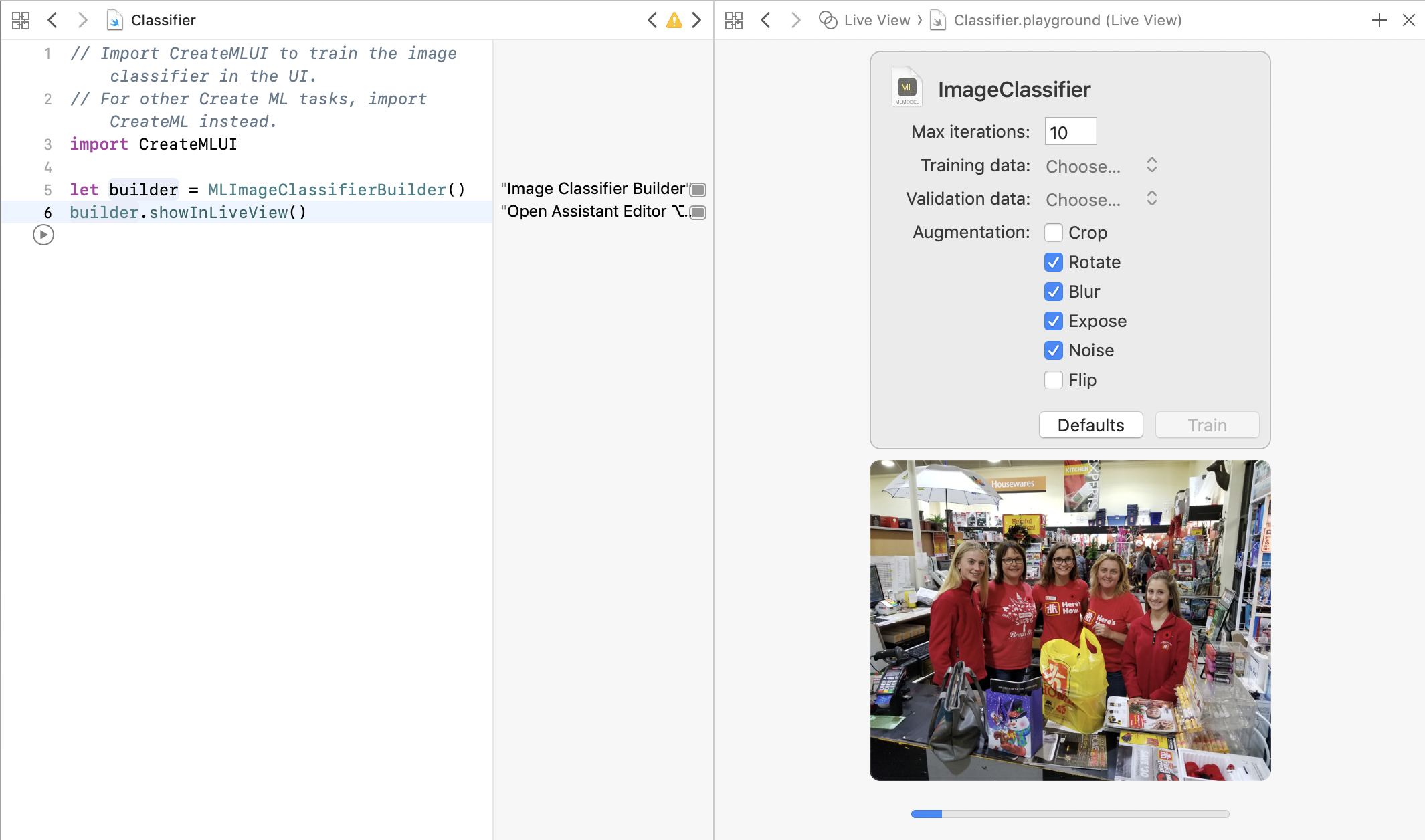
Apple’s new Create ML tool allows you to build a classifier by simply dragging in a folder. This was used to classify images as either singles, tens, or hundreds, as a first step in the ML pipeline.
3. Different densities, different prediction models: singles, tens, hundreds+
These crowd counting models (from the previous post) are heavily skewed to particular densities. For example, the model used to count three people, will have a hard time with one thousand people. They are based on the paper Multi-Scale Convolutional Neural Networks for Crowd Counting. To mitigate this, we have three models:
- singles: Uses Apple’s built in face detection (VNDetectFaceRectanglesRequest). You can beat it by showing the back of your head!
- tens: Uses the model overtrained for the ShakeCam in the previous crowd counting post, which has between zero to eighty people. The tens category desparately needs a newly trained model.
- hundreds: Uses a model built with the UCF Crowd dataset.
This would be the final step in the two step ML pipeline. These models, however, are still in the python Keras format. Let’s convert them to Core ML.
4. Python coremltools to convert Keras to Core ML
Apple’s coremltools convert existing Keras models to Core ML. It worked well with one exception: arbitrarily (not fixed) sized images.
The top variable sized layer had to be replaced with a fixed size layer to better work with Core ML. Variable sized input has come to Core ML, but support and documentation still has a way to go.
model = load_model(path)
# Create a new input layer to replace the (None,None,3) input layer
input_layer = InputLayer(input_shape=(675, 900, 3), name="input_1")
# Save
intermediary_path = "tmp/reshaped_model.h5"
model.layers[0] = input_layer
model.save(intermediary_path)
# Convert
coreml_model = coremltools.converters.Keras.convert(
intermediary_path,
input_names=['input_1'],
image_input_names=['input_1'],
output_names=['density_map'])
coreml_model.save("CrowdPredictor.mlmodel")
Now that we have our Core ML pipeline, a crowd classifier feeding into a crowd predictor, let’s see it in action.
5. Why an Xcode Playground for Core ML became a macOS App (Playgrounds are too brittle)
I was under the impression that the fastest way to a functional prototype was an Xcode Playground. Inspired by Create ML, the Xcode playground promised to be a quick and easy prototype for the iOS application.
When it works, it’s great.
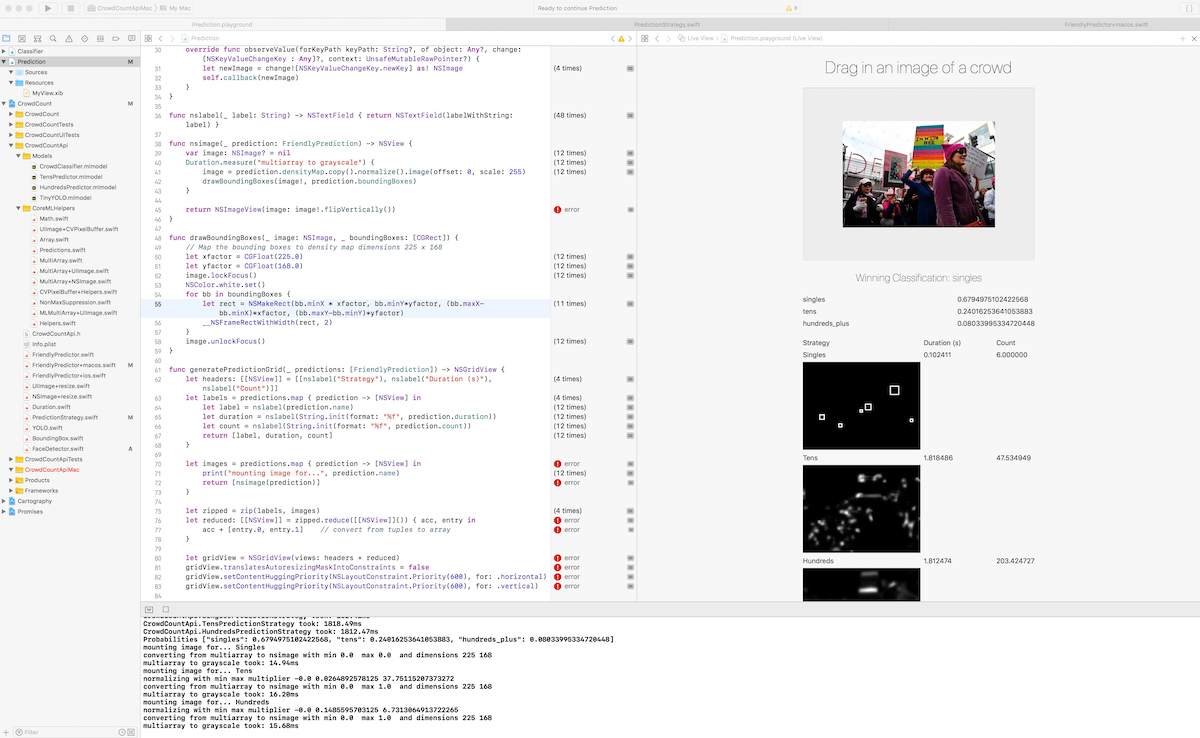
A significant downside to playgrounds however, is its inability to be an Xcode target, meaning it is unable to have linker and build dependencies. As you use CocoaPods or Cartography for third party library management, this will break you, and you’ll end up with spurious errors like the follow:
error: Couldn't lookup symbols:
type metadata for CrowdCountApiMac.FriendlyClassification
...
__swift_FORCE_LOAD_$_swiftCoreMedia
__swift_FORCE_LOAD_$_swiftCoreAudio
CrowdCountApiMac.FriendlyPredictor.DensityMapWidth.unsafeMutableAddressor : Swift.Int
...
The good news is that porting over to a macOS application is relativately straighforward, and will fix all of this. A macOS app is an Xcode target and can therefore link frameworks and binaries, allowing reliable compilation and linking.
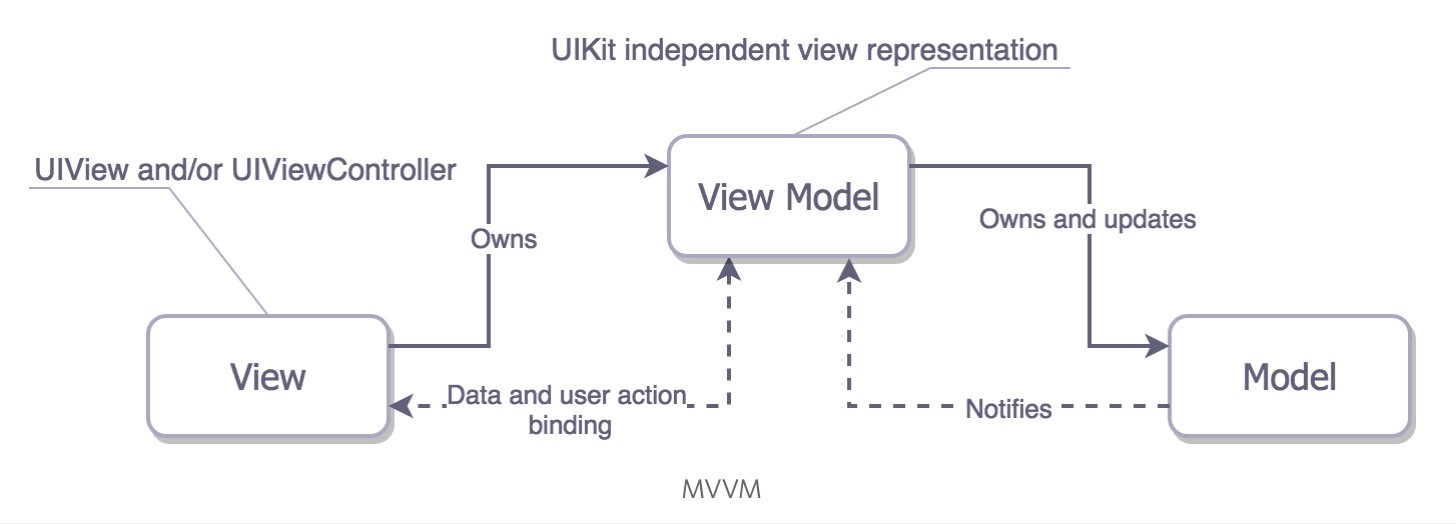
6. Swift Architecture: RxSwift and MVVM
RxSwift drove out an MVVM (Model-View-ViewModel) architecture, where Apple’s ViewControllers are the View. So really M(VC)VM. But these ViewController’s are lean, and merely drive the View or glue the VM.
There are many articles on this topic. Feel free to google for more information.
7. Performance: Better than expected
While extracting frames from the camera in real time, classification took ~100ms and crowd counting taking ~3 seconds. Good to see that iPhone X GPU being put to good use.
Word of advice: do not do your own image and MLMultiArray manipulation. Use Apple’s Vision API, such as VNImageRequestHandler, that makes better use of hardware.
8. Promising Future for Edge AI
The ability to run sophisticated neural networks, in this case a multi-column CNN, on your iPhone rather than the cloud, and in real time, is a watershed moment.
Sure, this already existed in applications like Prisma and Google translate, but the ease of development will present many more opportunities.
With millions of iPhones in use, it’ll be easier than ever to crowd source data from your willing users to improve your model, and create a virtuous cycle that will improve the product:
usage -> more data -> improved usage -> more data -> improved usage -> ...
This proof of concept shows that it’s doable, and that, in and of itself, is a milestone. Add in the performance and the iPhone’s ubiquity, and we have a promising future.